
La historia de los emoticones, y después, de los emojis nos sirve para entender algunos aspectos sobre el intercambio de información de diferentes sistemas y medios de comunicación entre usuarios de redes descentralizadas. Tanto los emoticones como los emojis están marcados por los medios de comunicación en los cuales fueron desarrollados.
El paso de comandos abstractos numéricos o en código a los entornos de iconos que nos son familiares como propios de las computadoras es uno de los principales logros en casi cuarenta años de programación basada en la experiencia del usuario. Cambiar de un lenguaje especializado a uno intuitivo, pictográfico como la metáfora del escritorio, los iconos de folders y archivos, el cursor, los programas, cada uno distinguible a través de una imagen, se debe en buena medida a la necesidad de que las computadoras fueran accesibles a las personas en general.
Tanto el emoticón como el emoji nacen de la necesidad directa de simplificar las comunicaciones entre miembros de comunidades virtuales. Ambas están codificadas ahora en Unicode, un estándar de codificación de caracteres diseñado para la codificación, transmisión y visualización de textos de múltiples idiomas, disciplinas técnicas y lenguas muertas.
ASCII
ASCII (acrónimo en inglés de American Standard Code for Information Interchange —Código Estándar Estadounidense para el Intercambio de Información—), es un código de caracteres basado en el alfabeto latino, originalmente de siete bytes, que fue creado en 1963. Publicado como estándar en 1967, y su última actualización es de 1987. Contiene 32 caracteres no imprimibles que sirven como caracteres de control que tienen como efecto procesar el texto y 95 caracteres imprimibles. ASCII fue diseñado para que hubiera concordancia en los caracteres entre diferentes sistemas y medios de comunicación y evitar con ello errores en la transmisión de información textual. Este estándar fue utilizado en sistemas como Usenet por lo que tuvo un extenso uso entre sistemas de comunicación descentralizados anteriores a la www.
Emoticón
El emoticón fue descubierto como medio de expresión en una Bulletin Board (BBS) del departamento de ciencias de la computación en la universidad de Carnegie Mellon en Pittsburgh, Estados Unidos en 1982. Los bulletin boards eran servers corriendo software que le permitían al usuario conectarse al sistema usando un programa. Al ingresar, el usuario podía subir y bajar datos, leer noticias y boletines, intercambiar mensajes con otros usuarios, publicar en los foros, conversar con otros usuarios. En pocas palabras, uno creaba una entrada donde la comunidad podía responder y comentar sobre la original. No pasó mucho tiempo para que las BBS fueran blanco de entradas de broma generadas por algún troll ocasional. Tras varias bromas sobre elevadores sospechosos en los BBS del campus de Carnegie Mellon se discutió la pertinencia de usar indicadores del sentido del discurso para alertar al público de cuál entrada se trataba de una broma y cuáles no. Por ello a las 11:44 am del 19 de septiembre de 1982, el científico Scott Fahlman sugirió una forma de informar a la comunidad qué entradas eran bromas:
Propongo que la siguiente secuencia de caracteres sea usada como marcador para las bromas :-) Aunque es probable, dando cuenta de las tendencias actuales que sea más económico marcar aquellas entradas que NO son bromas, para ello propongo que usemos :-(
No tardó mucho para que las BBS se llenaran de estos símbolos provenientes de ASCII, el estándar de codificación de caracteres publicado por primera vez en 1963 y revisado por última vez en 1986. Algunas de las creaciones más interesantes de la web temprana se conocen como arte en ASCII, son composiciones que consisten en pictogramas y otros patrones visuales hechos de caracteres provenientes de los códigos del estándar. La época de oro de estas creaciones tuvo lugar en la Usenet de la década de los ochenta. Una de las primeras creaciones virales entre los usuarios de Usenet fue “Espiando sobre la pared”.

La evolución de una idea pictográfica convertida por la inventiva de los usuarios en meme.

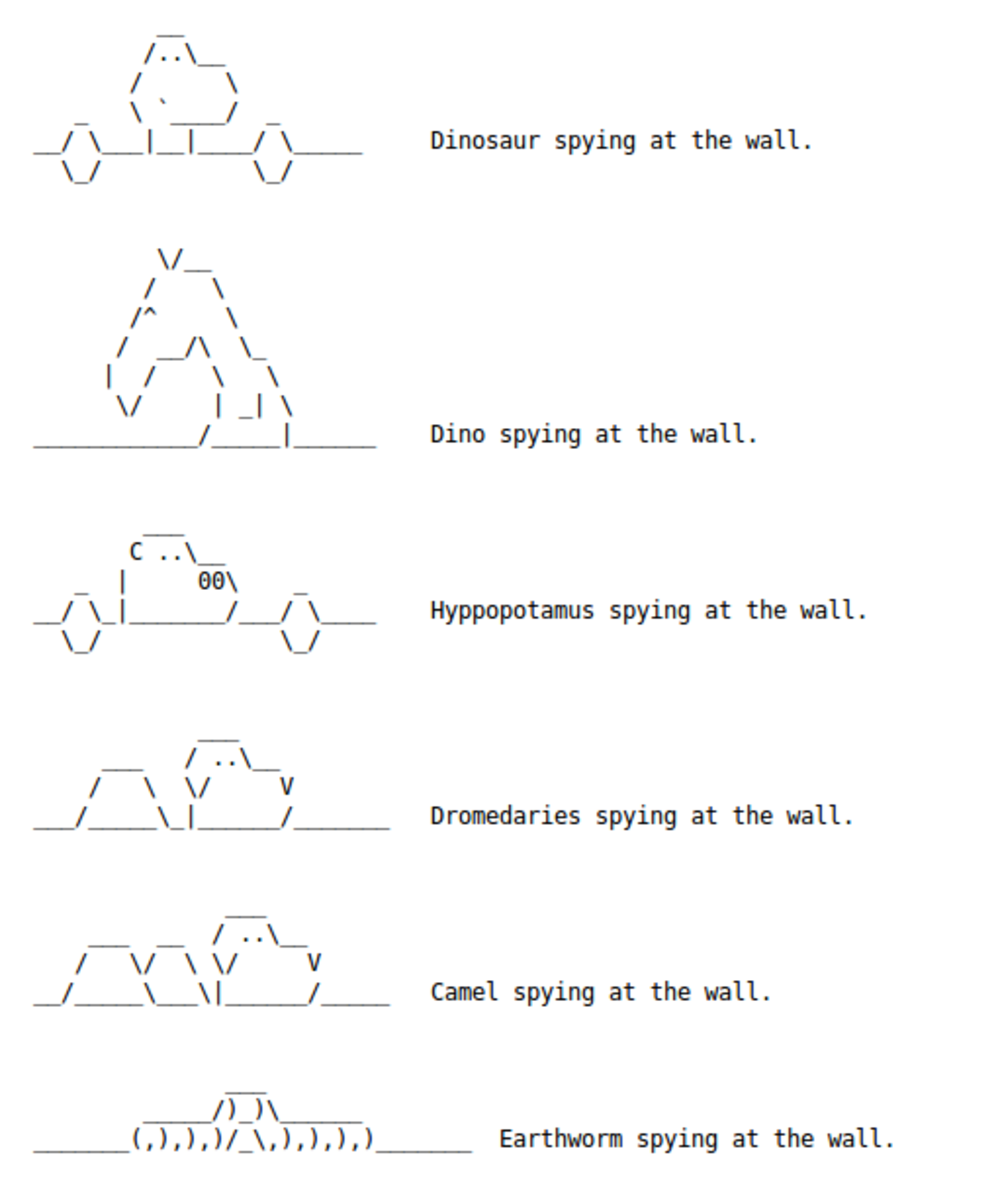
El estándar ASCII posibilitó la transmisión de imágenes compuestas por caracteres de texto en sistemas de comunicación descentralizados que no tenían la posibilidad de transmitir archivos de compresión de imágenes. Experimentos similares se dieron durante la década de los ochenta en sistemas como Videotexto en Brasil, donde Eduardo Kac realizó Reabracadabra, poemas visuales compuestos a través de caracteres de texto.
La introducción de interfaces gráficas para internet acabó con el periodo dorado del arte en ASCII, pero el fin de Usenet y el comienzo de la www, con la entrada pública a internet tras la venta de servicio para particulares por America Online, llevó el arte de ASCII a un público mayor y eventualmente al museo de arte.

Con los browsers comerciales como Mosaic, lanzado en 1993, el primer video en streaming el 24 de julio de 1993, y la carrera de los exploradores por las principales empresas de software para codificar video en internet y los formatos de las imágenes. Esos primeros años de los noventa nos traen la popularización del internet en la cultura popular, y los primeros movimientos artísticos de nativos digitales. Ejemplo del arte digital en ASCII como la página wwwwwwwww.jodi.org creada por el colectivo JODI en 1995 o “ASCII History of Moving Images” de Vuk Cosic realizada en 1998, quien convirtió extractos de videos de películas y series populares en imágenes compuestos por caracteres de ASCII, nos muestran el profundo impacto que ASCII generó en el arte después de internet, tanto así que en 1999 la película de los hermanos Wachowski, The Matrix, tomó la obra de Cosic para imaginarse como una ciudad simulada pudiera verse por alguien que la viera a través sus ilusiones.
El descubrimiento del emoticón como una forma de catalogar entradas en las BBS, tuvo la función importante de separar el ruido de los mensajes relevantes. Eventualmente las comunicaciones personales a partir de computadoras y posteriormente los dispositivos inteligentes requirió de formas para transmitir sentimientos y expresiones que al lenguaje escrito no le era cómodo. Expresiones como :-), <3, :-( resultan útiles para transmitir sentimientos que son más fáciles de entender de modo visual.
Unicode
Es un estándar mantenido por un consorcio técnico (UTC) que conforman varias de las empresas de informática a nivel global. El Consorcio de Unicode tiene relación con ISO/IEC, un estándar para la seguridad de la información con el que mantienen acuerdos sobre la sincronización de estándares que contienen los mismos caracteres y puntos de código. Creado en 1991, Unicode recoge todos los caracteres codificados en ASCII e intenta recopilar todos los caracteres posibles de diferentes idiomas para posibilitar la transmisión de estos caracteres entre diferentes dispositivos. Cuatro veces al año, el comité técnico se reúne para discutir las últimas actualizaciones y los nuevos caracteres que se añaden al estándar. La versión más reciente contiene 136,755 caracteres que cubren 139 diferentes scripts de lenguas modernas e históricas.
Emoji
A finales del siglo veinte, cuando en Japón las compañias de telecomunicaciones planearon implementar sistemas de telefonía celular con internet, la necesidad de simplificar la transmisión de mensajes de los usuarios era uno de los grandes problemas técnicos, debido a que el usuario, sobre todo adolescente, necesitaba buena parte del ancho de banda de transmisión para poder expresar ciertos sentimientos y emociones con la transmisión de imágenes en formatos comprimidos o en imágenes compuestas por caracteres como las de arte de ASCII. Muchas veces esto saturaba las líneas u obligaba a utilizar todos los caracteres posibles que el mensaje podía transmitir con ASCII. Así que se ideó un sistema de pictogramas que pudiera cubrir varios aspectos de la vida cotidiana, el cual estuviera dentro del código de caracteres escritos pero cuya representación visual fuera una imagen ideográfica de 144 píxeles. Dando como resultado el emoji, creado para simplificar las conversaciones entre usuarios y aligerar la transmisión de datos, debido a que al transmitir un emoji 😄 solo se transmite el código U+1F604, mientras que :-) se trasmite U+003A + U+002D + U+0029u.
El emoji nace en 1999, cuando Shigetaka Kurita se enfrentó con un problema que estaba dando dolor de cabeza a las compañías telefónicas japonesas que querían introducir el primer servicio de telefonía con internet: el aumento del uso de imágenes en las conversaciones o chats virtuales donde se usaban buena cantidad de bytes de información al transmitir imágenes que expresaban sus sentimientos y emociones. La lengua japonesa tiene algunas peculiaridades que, en la escritura de cartas y mensajes personales, resultan en textos largos y ampulosos, llenos de expresiones pomposas. La naturaleza corta y directa del email o el mensaje de texto suele conllevar malentendidos. En una conversación virtual uno no sabe cuál es el modo o tono discursivo del diálogo pues, por ejemplo, se carece de sonidos que puedan contextualizar la información. La compañía donde trabajaba Kurita tenía experiencia ofreciendo al público símbolos para sus conversaciones: en 1995 era muy popular su servicio de pager (conocido en México como biper) entre los adolescentes, en él se podía incluir el símbolo de corazón. Cuando la compañía decidió presentar un modelo de comunicación más ejecutivo y eliminó el símbolo de corazón, buena parte de su clientela abandonó el servicio y migró a otras compañías.
Kurita trabajaba en el primer proyecto de plataforma de internet móvil en Japón llamado “i-mode” de la compañía DoCoMo, quienes intentaban crear un servicio de telefonía celular con acceso a internet en un dispositivo con una pequeña pantalla de LCD donde sólo podían introducir 250 caracteres. En “i-mode” todo era transmitido en texto, pensando en la importancia de las imágenes para expresarse, Kurita tomó como ejemplo el uso de pictogramas en los pronósticos del tiempo. En los prototipos de “i-mode” se utilizaban complejos caracteres japoneses para indicar que el día sería soleado mientras que en los programas de televisión se usaba simplemente una icono del sol, eso detonó en Kurita una posible solución para liberar el ancho de banda: introducir signos ideográficos dentro del código de caracteres. Su propuesta fue aceptada y tuvo que diseñar los primeros 176 emojis en una plantilla de 12x12 pixeles. Tener menos caracteres facilita la transmisión, la idea de Kurita de proporcionar símbolos que se transmiten como un sólo carácter de código y que los sistemas operativos de los teléfonos los presenten como una imagen hizo completamente revolucionario al emoji.
Kurita, al no ser un diseñador ni artista, se enfrentó al problema prestando atención a diferentes elementos de su niñez, incluyendo manga y kanji, debido a que en los cómics japoneses se expresan muchos sentimientos y emociones de manera pictórica. Por ejemplo el sudor para indicar que se está agobiado, la bombilla si uno tiene una idea. Programados en la propia codificación de caracteres japonesa, los emojis se descarganban en los celulares de la compañía DoCoMo como cualquier otro caracter. Podrían ser utilizados cuando uno los seleccionaba, más o menos como ahora lo hacemos nosotros en nuestros celulares.
La internacionalización de los emojis comenzó en 2006, cuando la compañía estadounidense Apple decidió entrar al mercado de los celulares en Japón. Apple ahora celebra la inclusión y modificación de los emojis, pero en un inicio se pensó que los emojis no serían de interés para los demás usuarios fuera del mercado japonés, lo que sucedió fue que los usuarios alrededor del mundo descargaban el paquete de codificación de caracteres japoneses para poder usarlos. Es extraordinario que tanto emoticones como emojis fueron creados para poder excluir el ruido de los mensajes importantes en las comunicaciones virtuales y ahora son, si bien no el primer lenguaje global, sí el lenguaje de más rápida expansión de la historia de la humanidad. El diccionario de Oxford nombró el emoji como la palabra del año 2015. Estos pixeles ahora forman parte del acervo del MoMA en Nueva York.

Diseño de caracteres en Unicode.
Cuando se habló de ASCII se mencionó la existencia de caracteres no imprimibles que sirven para procesar el texto. En Unicode existen varios caracteres no imprimibles que sirven para modificar los caracteres visibles. El ejemplo es la forma con la que la actualización de 2015 de Unicode programó los distintos colores de piel y las familias. Veamos el ejemplo de las familias. 👩👩👧👦 está compuesto de siete caracteres de Unicode. Mujer, mujer, niña y niño, ilados todos por tres caracteres no visibles de ilación llamado Zero Width Joiner, o U+200D. De forma que 👩👩👧👦 está escrito en el código de Unicode como 👩 U+1F469, U+200D, 👩U+1F469, U+200D, 👧U+1F467, U+200D, 👦U+1F466. Este tipo de caracteres de ilación evitan la repetición de un mismo caracter con pequeñas variantes, por ejemplo las vocales y sus distintas acentuaciones posibles, y lo sustituye con pá sus una gran cantidad de caracteres por pequeñas variantes que pueden servir también para otros caracteres como los acentos o las diéresis.
¿Quienes y cómo deciden la existencia de nuevos emojis?
Esta pregunta surgió en la mente de de Mark Bramhill, un productor de radio y cine, mientras investigaba sobre emojis para un episodio de su podcast Welcome to Macintosh. Su interés inicial era hablar de la manera en que los emojis se han convertido en una nueva parte del lenguaje, una hablada y consensuada (casi) universalmente. Al entrevistar a Jeremy Burge, el creador de la Emojipedia, Bramhill descubrió que cualquier persona del mundo puede escribir una propuesta de nuevo emoji, así que decidió vivir el proceso en carne propia.
Cada cuatro años, los miembros de Unicode se reúnen para ponderar las nuevas propuestas de emojis. Una vez aprobados, los emojis son permanentes, no existe un proceso para eliminarlos. Para ser consideradas, las propuestas deben cumplir algunos requisitos: la demanda del emoji debe existir previamente, esto se tiene que sustentar con datos que respalden dicha demanda, citando el uso de hashtags en las redes sociales y datos de las tendencias de búsqueda en Google (una herramienta disponible para todos los usuarios). El emoji debe ser visualmente distintivo, es decir, no puede parecerse a ningún emoji existente en la librería de Unicode. La propuesta no puede ser algo rebuscado, ni tampoco algo vago, tampoco puede ser algo que resulte una moda pasajera, debe tener cierto grado de longevidad pues existirá por siempre.
Con lo anterior en mente, Bramhill decidió desarrollar una propuesta de emoji que representara las prácticas de yoga y meditación. En lugar de proponer la imagen de un tapete de yoga enrollado o una persona balanceándose sobre una pierna, se decidió por la figura de una persona sentada con las piernas cruzadas, en posición de flor de loto. Bramhill redactó su propuesta en 2016 y la respaldó con estadísticas de las tendencias de uso de Google trends de las palabras “meditación” y “yoga”, la existencia del “Día internacional de yoga” instaurado por unanimidad en las Naciones Unidas y con el hecho de que en Instagram el hashtag #Yoga es más popular que #Running (#correr en inglés).
La propuesta pasó el primer filtro y un año después, Bramhill recibió una invitación a participar en una audiencia presencial en California frente al comité técnico de Unicode. De ser aprobado, su emoji formará parte de la librería el próximo 2018. Para ello, las diversas plataformas como Google, Apple y Facebook tendrían que diseñar sus propias versiones del emoji, visible en los distintos dispositivos gracias a la estandarización del lenguaje Unicode.

acm y czp